Narodziny radzieckiego systemu obrony przeciwrakietowej. „El Burroughs”

Burtsev odziedziczył miłość i szacunek do zachodnich prototypów po swoim nauczycielu, tak, w zasadzie, począwszy od BESM-6, ITMiVT aktywnie wymieniał informacje z Zachodem, głównie z IBM w USA i University of Manchester w Anglii (to właśnie ta przyjaźń zmusił Lebiediewa, w tym h., do lobbowania na rzecz interesów brytyjskiej MLK, a nie niemieckiego Robotronu na pamiętnym spotkaniu w 1969 r.).
Oczywiście „Elbrus” nie mógł mieć prototypu, a sam Burcew otwarcie to przyznaje.
Odpowiedź jest jednoznaczna: „Tak”. Przed przystąpieniem do projektowania nowego komputera zawsze bardzo dokładnie studiowaliśmy rozwój całego świata w tej dziedzinie.
Pojawiło się wówczas pytanie o podniesienie poziomu języka maszynowego w celu zmniejszenia przepaści między językiem wysokiego poziomu a językiem poleceń w celu zwiększenia efektywności przekazywania programów napisanych w języku wysokiego poziomu.
W tym kierunku na świecie działały w trzech miejscach.
W ujęciu teoretycznym najpotężniejsze było dzieło Ailifa: „Zasady konstruowania podstawowej maszyny”, na Uniwersytecie w Manchesterze w laboratorium Kilburna i Edwardsa powstała maszyna MU-5 („Manchester University-5”), aw Burrows opracowano maszyny do zastosowań bankowych i wojskowych. .
Byłem we wszystkich trzech firmach, rozmawiałem z głównymi programistami i miałem niezbędne materiały na temat zasad zawartych w tych opracowaniach.
Projektując Elbrus-1 i Elbrus-2 MVK, wzięliśmy z zaawansowanych rozwiązań wszystko, co wydawało nam się wartościowe. Tak powstają wszystkie nowe maszyny i tak powinny być rozwijane.
Na rozwój Elbrus-1 i Elbrus-2 MVK miała wpływ architektura HP, 5E26, BESM-6 i szereg innych ówczesnych rozwiązań.
Pojawiło się wówczas pytanie o podniesienie poziomu języka maszynowego w celu zmniejszenia przepaści między językiem wysokiego poziomu a językiem poleceń w celu zwiększenia efektywności przekazywania programów napisanych w języku wysokiego poziomu.
W tym kierunku na świecie działały w trzech miejscach.
W ujęciu teoretycznym najpotężniejsze było dzieło Ailifa: „Zasady konstruowania podstawowej maszyny”, na Uniwersytecie w Manchesterze w laboratorium Kilburna i Edwardsa powstała maszyna MU-5 („Manchester University-5”), aw Burrows opracowano maszyny do zastosowań bankowych i wojskowych. .
Byłem we wszystkich trzech firmach, rozmawiałem z głównymi programistami i miałem niezbędne materiały na temat zasad zawartych w tych opracowaniach.
Projektując Elbrus-1 i Elbrus-2 MVK, wzięliśmy z zaawansowanych rozwiązań wszystko, co wydawało nam się wartościowe. Tak powstają wszystkie nowe maszyny i tak powinny być rozwijane.
Na rozwój Elbrus-1 i Elbrus-2 MVK miała wpływ architektura HP, 5E26, BESM-6 i szereg innych ówczesnych rozwiązań.
Tak więc Burtsev, w przeciwieństwie do wielu, przyznaje, że nie wahał się hojnie pożyczać pomysłów architektonicznych od swoich sąsiadów, a nawet mówi, gdzie szukać ogonów.
Skorzystajmy z hojnej oferty i odkopmy trzy źródła i trzy komponenty Elbrusa.

Pierwsza to monografia Johna Iliffe'a Basic Machine Principles (Macdonald & Co; 1. wydanie, 1 stycznia 1968) i jego artykuł Elements of BLM (The Computer Journal, tom 12, wydanie 3, sierpień 1969, strony 251 –258), druga to praktycznie nieznany komputer MU5 zbudowany jako eksperyment na Uniwersytecie w Manchesterze, a trzeci to seria Burroughs 700.
Czy to nie klon samego Burroughsa?
Zacznijmy rozumieć po kolei.
Po pierwsze, niektórzy czytelnicy mogli słyszeć termin „architektura von Neumanna” często używany w kontekście przechwałek: „tutaj zaprojektowaliśmy unikalny komputer inny niż von Neumann”. Oczywiście nie ma w tym nic wyjątkowego, choćby dlatego, że maszyn o architekturze von Neumanna nie budowano już w latach pięćdziesiątych.
Po pracy na ENIAC-u (który był programowany na zasadzie zakładek, z dużą ilością drutów płynących i nie było mowy o jakiejkolwiek kontroli obliczeń przez program załadowany do pamięci i nie było mowy) do następnej maszyny , zwany EDSAC, Mauchly i Eckert wymyślili główne pomysły na jego projekt.
Są to: jednorodna pamięć, w której przechowywane są polecenia, adresy i dane, różnią się one od siebie jedynie sposobem dostępu do nich i efektem, jaki powodują; pamięć jest podzielona na adresowalne komórki, aby uzyskać dostęp, należy obliczyć adres binarny; i wreszcie zasada sterowania programowego – działanie maszyny, to sekwencja operacji ładowania zawartości komórek z pamięci, manipulowania nimi i wyładowywania ich z powrotem do pamięci, pod kontrolą poleceń, które są sekwencyjnie ładowane z tej samej pamięć.
Niemal wszystkie maszyny (a było ich tylko kilkadziesiąt) wyprodukowane na świecie od 1945 do 1955 roku wypełniały te zasady, jako że zostały zbudowane przez naukowców akademickich, którzy byli szeroko zaznajomieni z Pierwszym Szkicem Raportu o EDVAC, rozesłanym do uniwersytetów przez kuratora von Neumanna przez Hermana Heinego Goldstine'a w jego imieniu.
Oczywiście nie mogło to trwać długo, ponieważ czysta maszyna von Neumanna była raczej matematyczną abstrakcją, jak maszyna Turinga. Przydatne było wykorzystanie go do celów naukowych, ale prawdziwe komputery zbudowane zgodnie z tymi pomysłami okazały się zbyt wolne.
Era czystych maszyn von Neumanna skończyła się już w latach 1955-1956, kiedy ludzie po raz pierwszy zaczęli myśleć o potokach, wykonywaniu spekulatywnym, architekturze opartej na danych i innych podobnych sztuczkach.
W roku śmierci von Neumanna w Laboratorium Naukowym Los Alamos uruchomiono komputer MANIAC II (Mathematical Analyzer Numerical Integrator and Automatic Computer Model II) z 5 lampami, 190 diodami i 3 tranzystorami.
Działał na 48-bitowych danych i 24-bitowych instrukcjach, miał 4 słów pamięci RAM i miał średnią prędkość 096 KIPS.
Maszyna została zaprojektowana przez Martina H. Grahama, który zaproponował zasadniczo nowy pomysł - oznaczanie danych w pamięci odpowiednimi znacznikami dla większej niezawodności i łatwości programowania.
W następnym roku Graham został zaproszony przez pracowników Rice University w Houston w Teksasie do pomocy w zbudowaniu komputera tak potężnego jak Los Alamos. Projekt R1 Rice Institute Computer trwał trzy lata, aw 1961 roku maszyna była gotowa (później zastąpiono ją standardowym IBM 7040 dla poważnych uniwersytetów amerykańskich i, jak na ironię, Burroughs B5500).
Schemat dekodowania 2 instrukcji na słowo, jak w MANIAC II, wydawał się Grahamowi zbyt fantazyjny, więc R1 działał na słowach 54-bitowych z instrukcjami o stałej szerokości dla całego słowa i miał podobną architekturę znaczników. Rzeczywista długość słowa wynosiła 63 bity, z czego 7 to kod korekcji błędów, a 2 to znacznik.
Mechanizm adresowania pośredniego R1 był znacznie bardziej zaawansowany niż IBM 709 - w rzeczywistości były to prawie gotowe deskryptory z przyszłych maszyn Burroughs. Graham był również utalentowanym inżynierem elektrykiem i wynalazł nowy typ ogniwa lampowo-diodowego dla R1, zwany Single Sided Gate, który umożliwił osiągnięcie doskonałej częstotliwości 1 MHz jak na tamte lata. Maszyna miała 15-bitowe adresy, 8 rejestrów danych/poleceń i 8 rejestrów adresowych.

Pierwsza generacja otagowanych architektur pojawiła się dosłownie zaraz po śmierci von Neumanna. Maszyny Ailifa i Grahama, po lewej część procesora MANIAC II, po prawej sam Ailif bierze udział w montażu głównej szafy R1. Zdjęcie https://www.sciencephoto.com i https://scholarship.rice.edu
Rice University dla USA jest czymś w rodzaju radzieckiego MINEP, więc nie dziwi fakt, że stworzenie komputera (który miał służyć do badania hydrodynamiki ropy) było częściowo finansowane przez Shell Oil Company.
Jej kuratorem był Bob Barton (Robert Stanley Barton), utalentowany inżynier elektronik. W 1958 roku ukończył kurs logiki matematycznej i notacji polskiej stosowanej w algebrze, po czym rozpoczął pracę w Burroughs, budując w 1961 roku legendarny B5000 w oparciu o architekturę stosu znaczników.
Nad oprogramowaniem R1 pracował ten sam Brytyjczyk Ilif. Jego zespół stworzył system operacyjny SPIREL, asembler symboliczny AP1 oraz język GENIE, który stał się jednym z prekursorów OOP. System operacyjny posiadał niezwykle zaawansowany mechanizm dynamicznej alokacji pamięci i wyrzucania elementów bezużytecznych, a także mechanizmy ochrony danych i kodu.
Dla swojego systemu operacyjnego Ailif opracował nowy mechanizm adresowania tablic, wykorzystujący wektor wskaźników do wektorów danych. Pomysł ten był tak zaawansowany w stosunku do adresowania w stylu Fortran (adres zawiera krok i przesunięcie dla każdego elementu tablicy), że został nazwany na cześć twórcy i od tego czasu wektory Ailif są używane wszędzie, od Ferranti Atlas po Javę, Python, Ruby, Visual Basic .NET, Perl, PHP, JavaScript, Objective-C i Swift.
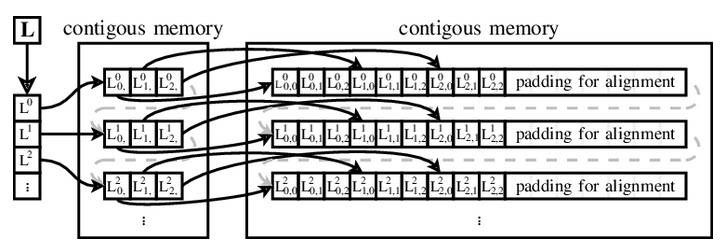
Wykorzystanie wektora Ailif do adresowania macierzy 3x3 (https://www.researchgate.net)
Pod koniec lat pięćdziesiątych teoretyczny model maszyny von Neumanna stanął przed wyzwaniem, na które nie było adekwatnej odpowiedzi (i dlatego całkowicie umarł).
Komputery stały się na tyle szybkie, że tylko jedna osoba nie mogła obciążyć ich pracą – pojawiła się koncepcja klasycznego komputera typu mainframe z dostępem do terminala i wielozadaniowym systemem operacyjnym.
Nie będziemy zagłębiać się w zawiłości, jakie czekają architektów na drodze do wielozadaniowości (wystarczy do tego każdy sensowny podręcznik projektowania systemów operacyjnych), zauważamy jedynie, że kluczowa dla jego implementacji jest reentrancja kodu, czyli możliwość uruchomienia kilka instancji tego samego programu w tym samym czasie, pracujących na różnych danych, dzięki czemu dane jednego użytkownika są chronione przed zmianami dokonanymi przez innego użytkownika.
Pozostawienie wszystkich tych problemów całkowicie na głowie architektowi OS i programistom systemu nie wydawało się zbyt dobrym pomysłem – złożoność tworzenia oprogramowania wzrosłaby za bardzo (pamiętajcie, jak projekt OS/360 zakończył się bajeczną porażką, Multics też nie startować).
Było też alternatywne wyjście - stworzenie odpowiedniej architektury dla samego komputera.
To właśnie te możliwości były rozważane niemal jednocześnie przez kolegów z R1 – praktyka Bartona, który zaprojektował B5000, oraz teoretyka Ailifa, który napisał bardzo podstawowe zasady maszynowe, które tak bardzo zainspirowały Burtseva.
ICL (z którą nigdy nie współpracowaliśmy) kierowała rozwojem zaawansowanych architektur od 1963 do 1968 (to na podstawie tej pracy powstał artykuł), Ilif zbudował dla nich prototyp BLM ze sprzętowymi metodami zarządzania pamięcią jeszcze bardziej zaawansowanymi niż w maszynach Burroughsa.
Główną ideą Ailif była próba uniknięcia standardowego dla innych systemów (i w tamtych latach powolnego i nieefektywnego) mechanizmu współdzielenia pamięci opartego wyłącznie na metodach programowych - przełączanie kontekstu (termin architektury systemu operacyjnego, oznaczający w prosty sposób tymczasowe rozładowanie i zapisywanie jednego uruchomionego procesu oraz ładowanie i uruchamianie innego) przez sam system operacyjny. Z jego punktu widzenia podejście sprzętowe z wykorzystaniem deskryptorów było znacznie wydajniejsze.
Projekt BLM został zamknięty w 1969 roku, ale jego rozwój został częściowo wykorzystany w zaawansowanej linii komputerów mainframe z serii ICL 2900 wprowadzonej na rynek w 1974 roku (którą, niestety, mogliśmy opracować wspólnie).
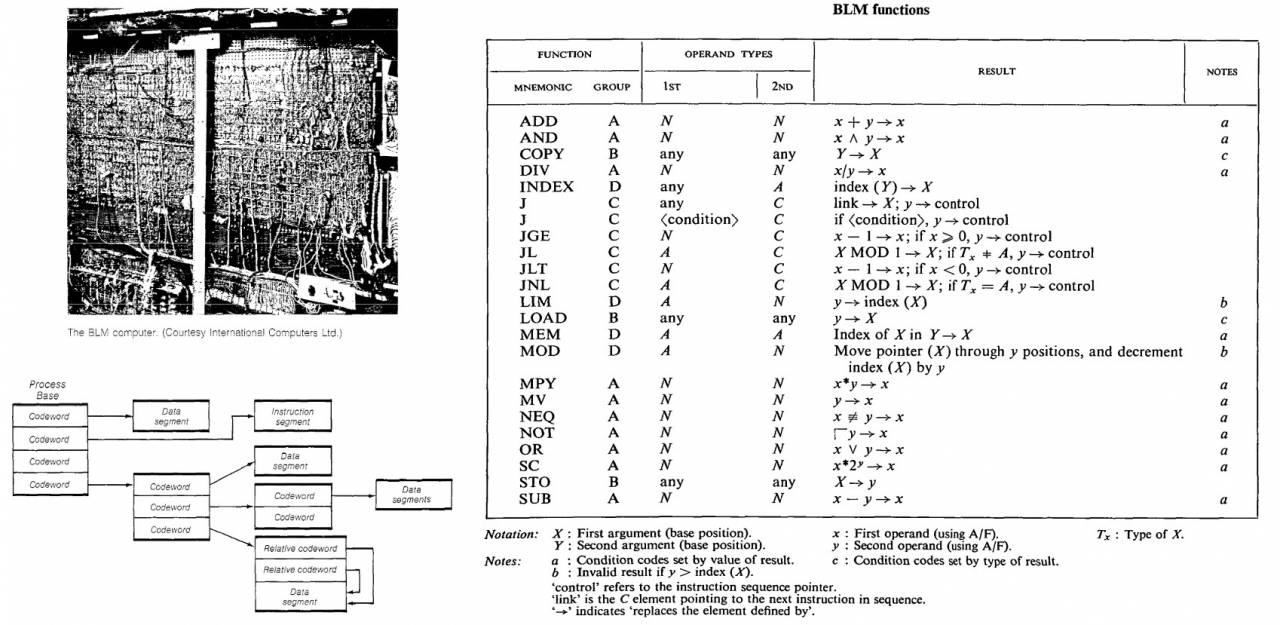
Druga generacja już tag-descriptor maszyn, niestety tylko to zdjęcie z książki Descriptor-Based Computer Systems (Levy, Henry M. 1984) pozostało z BLM. System poleceń jest odtworzony z oryginalnego artykułu Ailifa (aby czytelnicy mogli zagłębić się w problem po Burcewie).
Oczywiście problem skutecznej ochrony pamięci (a tym samym współdzielenia czasu) był w latach 1960. przedmiotem troski prawie wszystkich informatyków i korporacji.
Uniwersytet w Manchesterze nie stał z boku i zbudował swój piąty komputer o nazwie MU5.
Maszyna była rozwijana we współpracy z tą samą ICL od 1966 roku, komputer miał być 20 razy szybszy niż Ferranti Atlas pod względem wydajności. Rozwój trwał od 1969 do 1974 roku.
MU5 był kontrolowany przez system operacyjny MUSS i zawierał trzy procesory - sam MU5, ICL 1905E i PDP-11. Dostępne były wszystkie najbardziej zaawansowane elementy: architektura tag-deskryptor, pamięć asocjacyjna, wstępne pobieranie instrukcji, w ogóle - to był szczyt technologii tamtych lat.
Manchester Machine 5 - jedyne zdjęcie, doskonały opis systemu dowodzenia i architektury (https://ethw.org)
MU5 służył jako podstawa dla serii ICL 2900 i pracował na uniwersytecie do 1982 roku.
Ostatnim komputerem w Manchesterze był MU6, który składał się z trzech maszyn: MU66P, zaawansowanej implementacji mikroprocesora używanej jako komputer osobisty; MU66G to potężny skalarny superkomputer naukowy, a MU66V to system wektorowo-równoległy.
Naukowcy nie opanowali rozwoju architektury mikroprocesora, MU66G powstał i pracował na wydziale od 1982 do 1987 roku, a dla MU66V zbudowano prototyp na Motoroli 68k z emulacją operacji wektorowych.

Seria ICL 2900 była jedną z niewielu oryginalnych maszyn, które dość energicznie konkurowały z S/360. Dla brytyjskich użytkowników lat 1980. seria ta jest pełna ciepła i nostalgii, jak za radziecki BESM-6. Zdjęcie http://www.tavi.co.uk i http://www.computinghistory.org.uk
Dalszym postępem maszyn deskryptorowych miał być tzw. schemat. adresowanie oparte na możliwościach (dosłownie „adresowanie oparte na możliwościach”, nie ma ugruntowanego tłumaczenia na język rosyjski, ponieważ szkoła krajowa nie znała takich maszyn, w tłumaczeniu książki „Nowoczesna architektura komputerów: w 2 książkach” (Myers G.J., 1985) jest to bardzo trafnie nazwane adresowanie potencjalne).
Znaczenie potencjalnego adresowania polega na tym, że wskaźniki są zastępowane przez specjalne chronione obiekty, które mogą być tworzone tylko za pomocą uprzywilejowanych instrukcji wykonywanych tylko przez specjalny uprzywilejowany proces jądra systemu operacyjnego. Pozwala to jądru kontrolować, które procesy mogą uzyskiwać dostęp do których obiektów w pamięci, bez konieczności używania oddzielnych przestrzeni adresowych, a zatem bez narzutu związanego z przełączaniem kontekstu.
W efekcie pośrednim taki schemat prowadzi do jednorodnego lub płaskiego modelu pamięci - odtąd (z punktu widzenia nawet niskopoziomowego programisty sterowników!) Nie ma różnicy interfejsu między obiektem w pamięci RAM lub na dysku, dostęp jest absolutnie jednolite, przez wywołanie obiektu chronionego. Lista obiektów może być przechowywana w specjalnym segmencie pamięci (jak na przykład w Plessey System 250, stworzonym w latach 1969-1972 i reprezentującym sprzętowe ucieleśnienie bardzo ezoterycznego modelu obliczeniowego zwanego λ-calculus) lub zakodowana za pomocą specjalny bit, jak w prototypie IBM System /38.
Plessey System 250 został opracowany dla wojska i jako centralna maszyna sieci komunikacyjnej Departamentu Obrony był z powodzeniem używany podczas wojny w Zatoce Perskiej.
Ten komputer był absolutnym szczytem bezpieczeństwa sieci, maszyną, w której nie było superużytkowników z nieograniczonymi uprawnieniami jako klasa i nie było możliwości podniesienia swoich uprawnień poprzez hakowanie, aby robić to, czego nie powinno się robić.
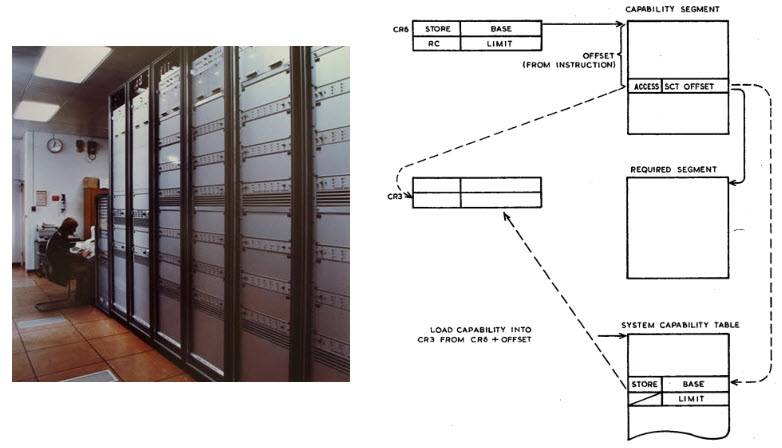
Pless 250 jedyne znane zdjęcie (ze zbiorów Kennetha J. Hamera-Hodgesa) oraz schemat działania adresowania potencjałów z monografii Capability Concept Mechanisms And Structure In System 250, DM England, 1974.
Taka architektura była uważana za niezwykle postępową i zaawansowaną w latach 1970-1980 i była rozwijana przez wiele firm i grup badawczych, maszyny komputerowe CAP (Cambridge, 1970-1977), Flex Computer System (Royal Signals and Radar Establishment, 1970), Three Rivers PERQ (Carnegie Mellon University i ICL, 1980-1985) i najsłynniejszy nieudany mikroprocesor Intel iAPX 432 (1981).
Zabawne, że inicjatorami 90% wszystkich najbardziej oryginalnych i dziwnych rozwiązań architektonicznych w latach 1960.-1970. byli Brytyjczycy (w latach 1980. – Japończycy, z podobnym skutkiem), a nie Amerykanie.
Brytyjscy naukowcy (tak, właśnie ci!) starali się jak najlepiej utrzymać na fali i potwierdzić swoje kwalifikacje jako wybitnych teoretyków informatyki. Szkoda tylko, że podobnie jak w przypadku radzieckiego akademickiego rozwoju komputerów, wszystkie te projekty były fenomenalne tylko na papierze.
ICL desperacko próbowała wejść do czołowych światowych producentów zaawansowanego żelaza, ale niestety nie wyszło.
Amerykanie początkowo myśleli, że anglosascy koledzy, biorąc pod uwagę ich pionierski wkład w informatykę od czasów Turinga, nie dadzą złych rad i dwukrotnie zostali ciężko spaleni - a Intel iAPX 432 i IBM System / 38 zawiodły sromotnie, co spowodował wielki zwrot połowy lat 1980-tych w kierunku nowoczesnych architektur procesorów (właśnie wtedy amerykańska szkoła inżynierii komputerowej odkryła zasadę działania maszyn RISC, która okazała się tak skuteczna ze wszystkich stron, że 99% współczesnych komputerów jest w jakiś sposób zbudowany według tych wzorów).

Komputer CAP nadal znajduje się w laboratorium Cambridge, prototyp IBM System/38 i stacja robocza Three Rivers PERQ (fot. https://en.wikipedia.org i https://www.chiark.greenend.org.uk)
Czasami jest to nawet interesujące – jakie zmiany wprowadziłaby pełnoprawna radziecko-brytyjska szkoła do lat 1980. ze swoją zaawansowaną kulturą produkcji, naszymi wspólnymi szalonymi pomysłami i zdolnością ZSRR do wstrzykiwania miliardów petrodolarów w rozwój?
Szkoda, że te możliwości zamknęły się na zawsze.
Naturalnie informacje o wszystkich zaawansowanych rozwiązaniach Brytyjczyków docierały do Burcewa dosłownie z pierwszej ręki i dzień po dniu, biorąc pod uwagę, że ITMiVT miał doskonałe kontakty z Uniwersytetem w Manchesterze (od wczesnych lat 1960. MLK, z którą Lebiediew tak bardzo chciał zawrzeć sojusz. Jednak Burroughs był jedyną komercyjną implementacją maszyn deskryptorów znaczników.
Co można powiedzieć o pracy Burtseva z tą maszyną?
Niewiarygodne przygody Burroughsa w Rosji
Sowiecka informatyka była bardzo zamkniętą dziedziną, dla wielu maszyn nie ma zdjęć, sensownych opisów (na przykład o architekturze Kitovskaya M-100 do tej pory tak naprawdę nic nie wiadomo), i w ogóle niespodzianki czyhają na każdym kroku (jak np. odkrycie w 2010 roku Komputer „Wołga”, którego istnienia nawet nie podejrzewali Rewicz, Malinowski i Małaszewicz, którzy przeprowadzili dziesiątki wywiadów i napisali na ich podstawie książki).
Ale w jednym konkretnym obszarze było więcej ciszy i tajemnic niż nawet w pojazdach wojskowych. Są to odniesienia do amerykańskich komputerów, które pracowały w Unii.
Temat ten był tak niechętnie poruszany, że można by odnieść wrażenie, że poza dobrze znanym CDC 6500 w Dubnej, w ZSRR jako klasa w ogóle nie było komputerów amerykańskich.
Nawet informacje o CYBRZE 170 i 172 musiały być wydobywane krok po kroku (a były HP 3000, które były w Akademii Nauk ZSRR i kilka innych!), ale obecność prawdziwego Burroughsa w Unii była rozważana przez wielu za mit.
Ani jednego rosyjskojęzycznego źródła, wywiadu, forum, książki - nigdzie nie ma nawet wiersza poświęconego losom tych maszyn w ZSRR. Jednak, jak zawsze, nasi zachodni przyjaciele wiedzą o nas znacznie więcej niż my sami.
W wyniku dokładnych poszukiwań ustalono, że Burroughs był bardzo kochany w Bloku Społecznym i używany z całą mocą, chociaż tutejsze źródła domowe miały wodę w ustach.
Na szczęście w USA jest wystarczająco dużo fanów tej architektury, którzy wiedzą o niej wszystko, łącznie z pełną liczbą instalacji każdego modelu swoich komputerów mainframe, aż do numerów seryjnych. Zebrali te informacje w tabeli, którą hojnie się podzielili, a dokument zawiera również źródła informacji dla każdej wysyłki komputerów Burroughs do krajów Układu Warszawskiego.
Sięgnijmy zatem do książki Economic Statecraft podczas zimnej wojny: europejskie reakcje na amerykańskie embargo handlowe, która ujawnia nam tajemnice sowieckich zamówień.
Na początku października 1969 r. międzyagencyjna grupa studyjna pracowników administracji… W tym czasie amerykańskie korporacje komputerowe rozpoczęły sprzedaż w Europie Wschodniej. Korporacja Burroughs z Detroit zainstalowała cztery ze swoich dużych komputerów B5500 w Czechosłowacji i jeden w Moskwie, które dorównywały komputerom IBM ze średniej półki. Radzieccy programiści i konserwatorzy zostali przeszkoleni w Detroit Plant.
Och, jak do 1969 roku Burroughs B5500 nie tylko zainstalowano w Moskwie, ale także sowieckim specjalistom udało się odbyć staż w fabryce firmy w Detroit!
Kolejne 4 samochody zostały sprzedane do Czechosłowacji na zamówienie rządowe, niestety nie wiadomo gdzie zostały zainstalowane i co robiły, ale oczywiście nie na uniwersytetach, kolumna „użytkownik” w tabeli wskazuje „rząd”. Najmocniejszy B6700 (później zmodernizowany do B7700!) był sprzedawany w NRD i używany na Uniwersytecie w Karlsruhe.
Dalsze próby wyjaśnienia informacji o dostawach do Moskwy zmusiły nas do kontaktu z Southwest Museum of Engineering, Communications and Computation (Arizona, USA).
Na ich stronie internetowej można znaleźć przypis do artykułu Alistaira Mayera z ACM's Computer Architecture News z 1982 roku (Alastair JW Mayer, The Architecture of the Burroughs B5000 – 20 Years Later and Still Ahead of the Times), list od inżyniera Rea Williamsa ) od zespołu instalacyjnego i wsparcia firmy Burroughs Corporation:
Dawno temu, nie pamiętam dokładnie roku, około 1973… Burroughs sprzedał B6500 (B6700) rosyjskiemu Ministerstwu Ropy. To był bardzo specjalny system z drukarkami cyrylicy, specjalnymi czytnikami taśmy papierowej i kilkoma innymi bardzo specjalnymi rzeczami. To było podczas zimnej wojny, ale my (Burroughs) mieliśmy specjalne pozwolenie na dostarczanie systemu. Uczestniczyłem w systemie „ride out” w zakładzie Miasto Przemysłu. Glen był z naszą organizacją TIO i pojechał do Rosji, aby pomóc w instalacji i szkoleniu miejscowej ludności w zakresie jego konserwacji. Opowiadał historie o GRU czy czymkolwiek, co nie ufało ich grom karcianym, ponieważ myśleli, że faceci z Burroughs „współpracują” czy coś w tym stylu i musieli zostawiać otwarte drzwi do pokoju. Świetne historie, szkoda, że nie pamiętam ich wszystkich. Więc na koniec dał mi pinezkę. Mam też kilka innych rzeczy, o których opowiem później.
Nawiasem mówiąc, Sowieci na cześć takiego wydarzenia wydali pamiątkowe odznaki z godłem Burroughsa i napisem „Kurczany” i rozdali je uczestnikom projektu. Oryginalna odznaka Williamsa zdobi tytuł tego artykułu.
Tak więc sowiecki przemysł naftowy (na ogół równoległy do całego bezprawia, jaki panował wokół naszych wojskowych i naukowych komputerów), będąc niezwykle wpływowym, bogatym i nieskończenie oddalonym od wszelkich starć Akademii i partii, nie chcąc zadowalać się domowe komputery (i absolutnie nie chcąc czegoś tam zamówić, zamówić u kogoś z sowieckich instytutów badawczych i czekać, aż po dziesięciu latach pojedynków wszystkie padną), spokojnie wzięła to i kupiła sobie najlepsze, co mogła - doskonałego B6700. Wezwali nawet zespół instalacyjny z korporacji, aby ta cenna maszyna działała prawidłowo.
Nic dziwnego, że ten odcinek, który dobitnie pokazuje, jak naprawdę poważni ludzie (nie zapominajmy, że nafciarze przywieźli do kraju większość pieniędzy, które wojsko i naukowcy wydawali następnie na swoje gry) traktowali samochody domowe, starali się zapomnieć silniejszy.

Burroughs B6700 z University of Tasmania i najnowszy w linii Burroughs Large Systems - wspaniały B7900 (http://www.retrocomputingtasmania.com, https://pretty-little-fools.tumblr.com)
Zwracamy uwagę na dwa interesujące fakty.
Po pierwsze, pomimo tego, że wszyscy znają Burroughsa głównie z dostarczania swoich komputerów typu mainframe (jako złotego standardu bezpiecznej architektury) dla Rezerwy Federalnej USA, mieli też zamówienia wojskowe (choć znacznie mniej niż IBM i Sperry, które w czasie II wojny światowej wojny nie udało im się nawiązać kontaktów z rządem).
A poza tym ich samochody bardzo, bardzo lubili uniwersytety. Można nawet powiedzieć – pokochali to na całym świecie: w Wielkiej Brytanii, Francji, Niemczech, Japonii, Kanadzie, Australii, Finlandii, a nawet Nowej Zelandii zainstalowano ponad sto komputerów Burroughs różnych linii. Architektonicznie (i pod względem stylu) Burroughs był Apple wielkiego komputera.
Ich maszyny były wytrzymałe i fenomenalnie niezawodne, drogie, wydajne, dostarczane jako absolutny zestaw ze wszystkimi wstępnie zainstalowanymi i skonfigurowanymi programami i pakietami oprogramowania, architektura była zamknięta, inna niż wszystko na rynku.
Uwielbiali je intelektualiści wszelkiego rodzaju, ponieważ Burroughs (podobnie jak Macintosh ze złotej ery) po prostu podłączali i grali. Jak na standardy komputerów mainframe tamtych lat, nawet tak udanych jak S/360, było niesamowicie fajnie.
I oczywiście różniły się konstrukcją, zastrzeżonymi wygodnymi terminalami, oryginalnym systemem ładowania płyt i wieloma innymi rzeczami. Zauważamy również, że w swoich latach był to wprawdzie nie superkomputer, ale potężna działająca maszyna, która wyprodukowała około 2 MFLOPS - kilka razy mocniejsza niż wszystko, co ZSRR miał w tym momencie.
W sumie uczelnie zasłużenie je pokochały, więc wykorzystanie Burroughsa jako naukowego superkomputera w Unii byłoby w pełni uzasadnioną decyzją. Osobną premią było wsparcie sprzętowe dla Algola, języka, który był uważany, po pierwsze, za złoty standard szkolnictwa wyższego (zwłaszcza w Europie), a po drugie, wyjątkowo wolny na innych architekturach.
Algol (którego pełne wsparcie nie pojawiło się w czysto domowych maszynach) został zasłużenie uznany za standard klasycznego akademickiego programowania strukturalnego. Nie przeładowany ezoterycznymi konstrukcjami jak PL/I, nie tak anarchiczny jak Pure C, wielokrotnie wygodniejszy niż Fortran, o wiele mniej zagmatwany niż LISP i (nie daj Boże) Prolog.
Przed nadejściem koncepcji OOP nie stworzono nic doskonalszego i wygodniejszego, a Burroughsy były jedynymi maszynami, na których nie zwalniał.
Na szczególną uwagę zasługuje jeszcze jeden fakt.
KoCom kategorycznie nie pozwalał nam na zakup zaawansowanych architektur, nawet restrykcje na potężne stacje robocze z lat 1980-tych zostały zniesione dopiero po rozpadzie ZSRR, musieliśmy zaciekle walczyć o CDC, CYBER sprzedał się ze zgrzytem (jak już wspominaliśmy, dyrektor Control Data był już badany przez Kongres w sprawie działań antyamerykańskich), zainstalowano kilka maszyn z celami w interesie Stanów Zjednoczonych.
CYBER z Centrum Hydrometeorologicznego otrzymaliśmy za pomoc z danymi o klimacie arktycznym, a CYBER LIAN w zamian za obietnicę wspólnego opracowania komputerów rekurencyjnych.
W rezultacie, nawiasem mówiąc, zostały sprzedane na próżno, wspólna praca nie wyszła.
Prawdziwy autor pomysłu, Torgaszow, został szybko zepchnięty do piekła przez swoich szefów, gdy tylko na horyzoncie pojawiła się sława i pieniądze ze współpracy z Jankesami. Przybyli Amerykanie, próbowali wydobyć jakieś gesty w rozwoju od szefów, którym trudno było sobie wyobrazić, jak działają zwykłe maszyny, w końcu splunęli na wszystko i wyszli.
Tak więc ZSRR stracił kolejną szansę wejścia na rynek światowy.
Ale świeże Burroughsy dostarczane są do nas bez mrugnięcia okiem, ani CoCom, ani Kongres nie sprzeciwiają się, żadnych skarg. Można to uzasadnić jedynie interesami wielkiego biznesu.
Sprzedali go naftowcom z gwarancją, że oczywiście nie oddadzą swojego uroku wojsku, sami go potrzebują, ale przyjaźń z sowieckim przemysłem naftowym jest bardzo korzystna dla obu stron.
Zauważamy również, że zaczęli nam sprzedawać Burroughsa właśnie w latach Breżniewa, kiedy intensywność zimnej wojny znacznie się zmniejszyła, jak pisaliśmy w poprzednich artykułach. Jednocześnie przebiegli Jankesi nie spieszyli się z pompowaniem swoich przeciwników technologiami czysto wojskowymi (takimi jak najpotężniejszy CDC 6600 lub Cray-1), ale nie przeszkadzało im wspieranie radzieckiego biznesu.
W rozprawie doktorskiej z administracji biznesowej Petera Wolcotta z University of Arizona Soviet Advanced Technology: The Case of High-Performance Computing, opublikowanej w 1993 roku, stwierdza się jednak, że B6700 został zainstalowany w Moskwie w 1977 roku (to znaczy wszystkie aprobaty i dostawa trwała łącznie 4 lata!).
Większość wstępnych prac projektowych nad Elbrusem zakończono w latach 1970-1973, kiedy Burtsev mógł zobaczyć żywy samochód tylko w USA (niestety nie ma informacji, kiedy dokładnie tam pojechał).
W tym czasie inżynierowie ITMiVT mieli dostęp tylko do ogólnej dokumentacji B6700 - architektury instrukcji i schematów blokowych maszyny. Wolcott pisze, że dokładniejsze informacje otrzymali w latach 1975-1976 (podobno po wycieczce Burcewa, który przywiózł plik dokumentów), co doprowadziło do pewnych ulepszeń i zmian w strukturze Elbrusa.
Wreszcie, w 1977 roku, deweloperzy szczegółowo przestudiowali Moscow Burroughs, co doprowadziło do kolejnej fali ulepszeń, prawdopodobnie z tym, w tym ciągłego procesu wprowadzania zmian w dokumentach, które już wchodziły do produkcji.
Dzięki temu możemy zagwarantować, że Burcewa nawiedziła inspiracja, wyraźnie pod wpływem przede wszystkim twórczości Brytyjczyków, z którymi mógł się zapoznać w połowie lat 1960. I tak, w tamtych czasach kierunek maszyn tagowania-deskryptorów rzeczywiście był uważany za „teoretycznie najpotężniejszy”, to znaczy był wspierany, jako najbardziej obiecujący, przez prawie całą akademicką informatykę w Wielkiej Brytanii.
Pod tym względem prace nad Elbrusem były zgodne z najbardziej zaawansowanymi wówczas badaniami i nie jest winą brytyjskich naukowców, że w połowie lat 1980. świat obrócił się w zupełnie innym kierunku.
Zauważamy również, że według artykułów teoretycznych zespołowi Burtsev nie udało się zbudować samochodu, dopiero zapoznanie się z dokumentacją na żywo Burroughs pozwoliło im w pełni zrozumieć, jak to działa.
Porównanie architektury
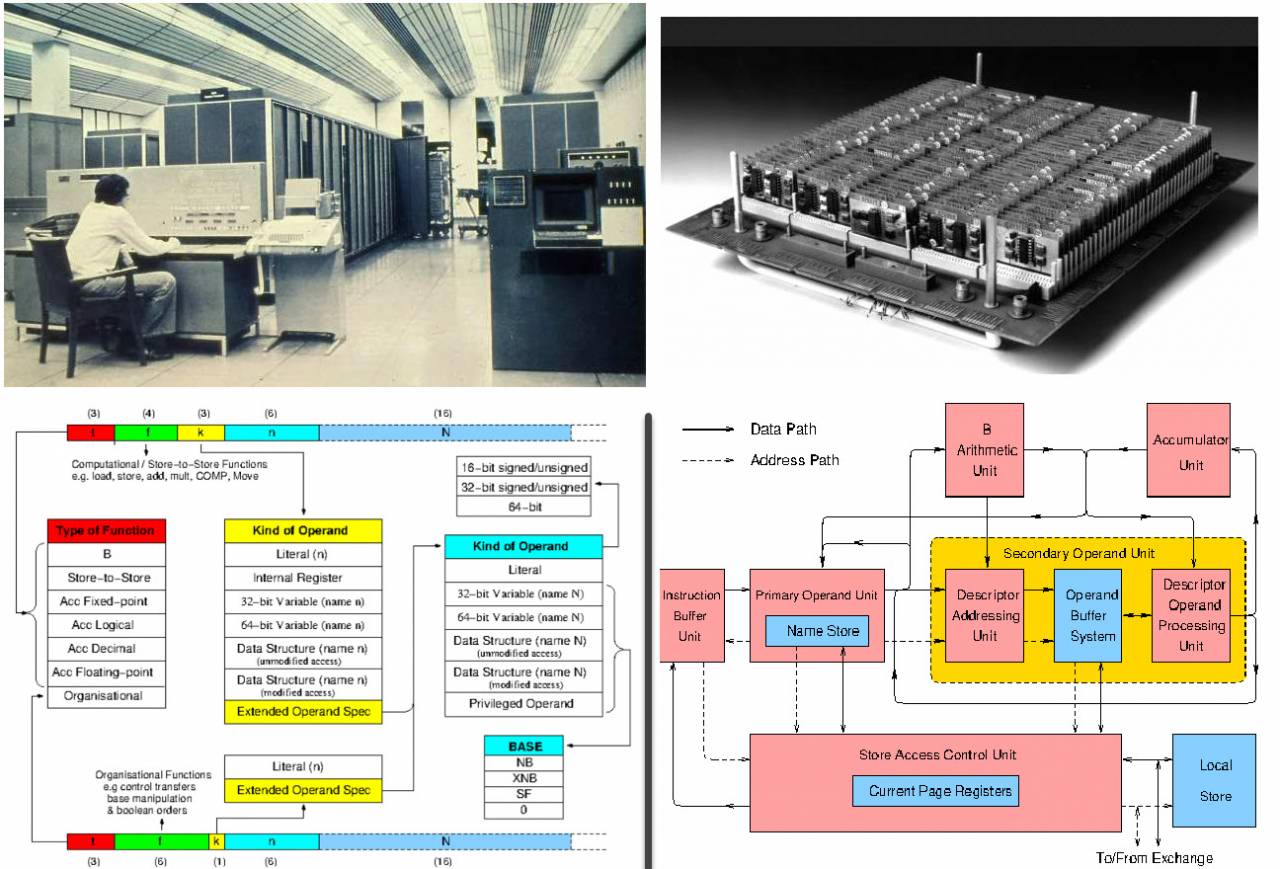
Cała linia Burroughs Large Systems Group została zbudowana na pojedynczej architekturze B5000. Oznaczenia maszyn były niezwykle ekstrawaganckie. Ostatnie trzy cyfry oznaczały generację maszyn, a pierwsza numer seryjny pod względem mocy w generacji.
Tym samym do dyspozycji mieliśmy serię 000 (jedynym przedstawicielem jest przodek B5000), potem numery od 100 do 400 nie były używane (poszły do Systemów Średnich i Systemów Małych), a kolejna seria otrzymała indeks 500. Miał trzy komputery podzielone według mocy - prostszy (B5500), bardziej skomplikowany (B6500) i teoretycznie najpotężniejszy (B8500).
Jednak B6500 już utknął w martwym punkcie, w wyniku czego seria utknęła na młodszym modelu. Odpadł też kolejny numer 600 (żeby nie mylić z CDC), i tak pojawiła się linia B5700, B6700 i B7700.
Różniły się one ilością pamięci, liczbą procesorów i innymi architektonicznie nieistotnymi detalami. Wreszcie ostatnia linia to 800. seria dwóch modeli (B6800 i B7800) oraz 900. z trzech (B5900, B6900 i B7900).
Cały kod napisany dla dużych systemów jest ponownie wprowadzany po wyjęciu z pudełka, a programista systemu nie musi w tym celu podejmować żadnych dodatkowych wysiłków. Mówiąc prościej, programista po prostu napisał kod, w ogóle nie myśląc, że może działać w trybie wielu użytkowników, system przejął nad nim kontrolę.
Nie było asemblera, język systemu był nadzbiorem ALGOL - języka ESPOL (Executive Systems Problem Oriented Language), w którym napisane zostało jądro systemu operacyjnego (MCP, Master Control Program) i całe oprogramowanie systemowe.
W serii 700 został zastąpiony przez bardziej zaawansowany NEWP (New Executive Programming Language). Opracowano dwa kolejne rozszerzenia do wydajnej pracy z danymi - DCALGOL (data comms ALGOL) i DMALGOL (Data Management ALGOL) oraz pojawił się osobny język wiersza poleceń WFL (Work Flow Language) do sprawnego zarządzania MCP.
Kompilatory Burroughs COBOL i Burroughs FORTRAN zostały również napisane w ALGOL i starannie zoptymalizowane, aby uwzględnić wszystkie niuanse architektury, dzięki czemu wersje tych języków dla dużych systemów były najszybsze na rynku.
Głębia bitowa dużych maszyn Burroughsa wynosiła konwencjonalnie 48 bitów (+ 3 bity znaczników). Programy składały się z bytów specjalnych – 8-bitowych sylab, które mogły być wywołaniem nazwy, wartości lub tworzyć operatora, których długość wahała się od 1 do 12 sylab (była to istotna innowacja serii 500, klasyczny B5000 używał stałych instrukcji o długości 12 bitów).
Sam język ESPOL miał mniej niż 200 instrukcji, z których wszystkie mieszczą się w 8-bitowych sylabach (w tym potężne operatory edycji linii i tym podobne, bez nich było tylko 120 instrukcji). Jeśli usuniemy operatory zarezerwowane dla systemu operacyjnego, takie jak MVST i HALT, zestaw powszechnie używany przez programistów na poziomie użytkownika będzie mniejszy niż 100. Niektóre operatory (takie jak Name Call i Value Call) mogą zawierać jawne pary adresów, inne używane zaawansowany stos rozgałęzień.
Burroughs nie posiadał rejestrów dostępnych dla programisty (dla maszyny szczyt stosu i następny były interpretowane jako para rejestrów), odpowiednio nie było potrzeby pracy z nimi przez operatorów, a różne sufiksy/przedrostki Nie były też potrzebne wskazania opcji wykonywania operacji między rejestrami, ponieważ wszystkie operacje były stosowane na wierzchu stosu. To sprawiło, że kod był wyjątkowo gęsty i zwarty. Wielu operatorów było polimorficznych i zmieniało swoją pracę zgodnie z typami danych zdefiniowanymi przez znaczniki.
Na przykład w zestawie instrukcji Large Systems jest tylko jedna instrukcja ADD. Typowy nowoczesny asembler zawiera kilka operatorów dodawania dla każdego typu danych, takich jak add.i, add.f, add.d, add.l dla liczb całkowitych, zmiennoprzecinkowych, podwójnych i długich. W Burroughs architektura rozróżnia tylko liczby o pojedynczej i podwójnej precyzji - liczby całkowite to po prostu liczby rzeczywiste z wykładnikiem równym zero. Jeśli jeden lub oba operandy mają znacznik 2, wykonywane jest dodawanie podwójnej precyzji, w przeciwnym razie znacznik 0 wskazuje pojedynczą precyzję. Oznacza to, że kod i dane nigdy nie mogą być niekompatybilne.
Praca ze stosem w Burroughs jest zaimplementowana bardzo pięknie, nie będziemy zanudzać czytelników szczegółami, po prostu uwierzcie nam na słowo.
Zauważmy tylko, że operacje arytmetyczne zajmowały jedną sylabę, operacje stosowe (NAMC i VALC) zajmowały dwie, gałęzie statyczne (BRUN, BRFL i BRTR) zajmowały trzy, a długie literały (na przykład LT48) zajmowały pięć. W rezultacie kod był znacznie gęstszy (a dokładniej mówiąc, miał większą entropię) niż we współczesnej architekturze RISC. Zwiększenie gęstości zmniejszyło liczbę chybionych instrukcji w pamięci podręcznej, a tym samym poprawiło wydajność.
Z architektury systemu odnotowujemy SMP - wieloprocesor symetryczny do 4 procesorów (jest to w serii 500, począwszy od serii 800, SMP został zastąpiony przez NUMA - Non-uniform memory access).
Burroughs byli generalnie pionierami w stosowaniu wielu procesorów połączonych szybką magistralą. Linia B7000 mogła mieć do ośmiu procesorów, pod warunkiem, że przynajmniej jeden z nich był modułem I/O. B8500 miał mieć 16, ale ostatecznie został odwołany.
W przeciwieństwie do Seymoura Craya (oraz Lebiediewa i Mielnikowa), inżynierowie Burroughs opracowali idee architektury masowo równoległej - łącząc wiele stosunkowo słabych procesorów równoległych ze wspólną pamięcią, zamiast używać jednego supermocnego procesora wektorowego.
Jak pokazano historia To podejście okazało się najlepsze.
Ponadto Large Systems były pierwszymi maszynami stosowymi na rynku, a ich idee później stworzyły podstawę języka Forth i komputerów HP 3000. Burroughs był pionierem wykorzystania tzw. stos saguaro (to taki kaktus, więc nazywają stos z gałęziami). Wszystkie dane były przechowywane na stosie, z wyjątkiem tablic (które mogły zawierać zarówno ciągi znaków, jak i obiekty), strony były dla nich przydzielane w pamięci wirtualnej (pierwsza komercyjna implementacja tej technologii, wyprzedzająca S/360).
Innym dobrze znanym aspektem architektury dużych systemów było stosowanie znaczników. Ta koncepcja pierwotnie pojawiła się w B5000 w celu zwiększenia bezpieczeństwa (gdzie tag po prostu oddzielał kod i dane, jak nowoczesny bit NX), począwszy od serii 500. rola tagów została znacznie rozszerzona. Przydzielono im 3 bity zamiast 1, więc łącznie dostępnych było 8 opcji znaczników. Niektóre z nich to: SCW (Software Control Word), RCW (Return Control Word), PCW (Program Control Word) i tak dalej. Piękno tego pomysłu polegało na tym, że bit 48 był tylko do odczytu, więc nieparzyste znaczniki oznaczały słowa kontrolne, których użytkownik nie mógł zmienić.
Stos jest bardzo dobry, ale jak pracować z obiektami, które nie mieszczą się w nim ze względu na swoją budowę, na przykład sznurki? W końcu potrzebujemy wsparcia sprzętowego do pracy z tablicami.
Bardzo prosto, Large Systems używa do tego deskryptorów. Deskryptory, jak sama nazwa wskazuje, opisują obszary przechowywania struktur, a także żądania I/O i wyniki. Każdy deskryptor zawiera pole wskazujące jego typ, adres, długość oraz czy dane są przechowywane w sklepie. Oczywiście są one oznaczone własną metką. Bardzo ciekawa jest również architektura deskryptorów Burroughsa, ale nie będziemy się tu wdawać w szczegóły, tylko zauważymy, że za ich pośrednictwem została zaimplementowana pamięć wirtualna.
Różnica między Burroughs a większością innych architektur polega na tym, że używają one stronicowanej pamięci wirtualnej, co oznacza, że strony są stronicowane w porcjach o stałej wielkości, niezależnie od struktury zawartych w nich informacji. Pamięć wirtualna B5000 współpracuje z segmentami o różnych rozmiarach, które są opisane deskryptorami.
W ALGOL granice tablic są całkowicie dynamiczne (w tym sensie Pascal ze swoimi statycznymi tablicami jest znacznie bardziej prymitywny, chociaż jest to naprawione w wersji Burroughs Pascal!), aw dużych systemach tablica nie jest przydzielana ręcznie, kiedy jest deklarowana , ale automatycznie po uzyskaniu do niego dostępu.
W rezultacie nie są już potrzebne wywołania systemowe niskiego poziomu alokacji pamięci, takie jak legendarny malloc w C. Usuwa to ogromną warstwę wszelkiego rodzaju autoportretów, z których C jest tak znany, i oszczędza programistę systemu przed kilka skomplikowanych i ponurych rutyn. W rzeczywistości duże systemy to maszyny obsługujące wyrzucanie elementów bezużytecznych a la JAVA i sprzętowo!
Jak na ironię, wielu użytkowników Burroughsa, którzy przerzucili się na niego w latach 1970. i 1980. i przeportowali swoje (pozornie poprawne!) programy z języka C, znalazło w nich mnóstwo błędów związanych z przepełnieniem bufora.
Problem fizycznych ograniczeń długości deskryptora, który nie pozwalał na bezpośrednie zaadresowanie więcej niż 1 MB pamięci, został elegancko rozwiązany pod koniec lat 1970. wraz z pojawieniem się mechanizmu ASD (Advanced Segment Descriptors), który umożliwił przydzielić terabajty pamięci RAM (w komputerach osobistych pojawiło się to dopiero w połowie 2000 roku - X).
Ponadto tzw. Przerwania p-bitowe, oznaczające, że blok pamięci wirtualnej został przydzielony, mogą być używane w Burroughs do analizy wydajności. Na przykład w ten sposób można zauważyć, że procedura przydzielająca tablicę jest stale wywoływana. Dostęp do pamięci wirtualnej drastycznie zmniejsza wydajność, dlatego nowoczesne komputery zaczynają działać szybciej, jeśli podłączysz inny układ pamięci RAM.
W maszynach Burroughs analiza przerwań p-bitowych pozwoliła nam znaleźć problem systemowy w oprogramowaniu i lepiej zrównoważyć obciążenie, co jest ważne dla komputerów typu mainframe działających 24 godziny na dobę, 7 dni w tygodniu. W przypadku dużych maszyn zaoszczędzenie nawet kilku minut czasu dziennie przełożyło się na dobry końcowy wzrost wydajności.
Wreszcie tagi, podobnie jak tagi, były odpowiedzialne za znaczny wzrost bezpieczeństwa kodu. Jednym z najlepszych narzędzi, jakie haker ma do skompromitowania nowoczesnych systemów operacyjnych, jest klasyczne przepełnienie bufora. W szczególności język C wykorzystuje najbardziej prymitywny i podatny na błędy sposób oznaczania końca linii, używając bajtu zerowego jako sygnalizatora końca linii w samym strumieniu danych (ogólnie rzecz biorąc, taka niechlujność wyróżnia wiele rzeczy tworzonych można by rzec po akademicku, czyli ludzi inteligentnych, którzy nie mają jednak specjalnych kwalifikacji w dziedzinie rozwoju).
W Burroughs wskaźniki są zaimplementowane jako i-węzły. Podczas indeksowania są one sprawdzane sprzętowo przy każdym zwiększeniu/zmniejszeniu, aby uniknąć przekroczenia granic bloku. Podczas dowolnego odczytu lub kopiowania zarówno blok źródłowy, jak i docelowy są kontrolowane przez deskryptory tylko do odczytu w celu zachowania integralności danych.
W rezultacie znaczna klasa ataków staje się w zasadzie niemożliwa, a wiele błędów w oprogramowaniu można wychwycić nawet na etapie kompilacji.
Nic dziwnego, że Burroughs jest tak uwielbiany przez uniwersytety. W latach 1960. i 1980. wykwalifikowani programiści z reguły pracowali w dużych korporacjach, naukowcy pisali dla siebie oprogramowanie, w wyniku czego Large Systems ogromnie ułatwił im pracę, uniemożliwiając fundamentalne schrzanienie w jakimkolwiek programie.
Burroughs wywarł wpływ na ogromną liczbę technologii.
Jak już powiedzieliśmy, linia HP 3000, a także ich legendarne kalkulatory, które są nadal w użyciu, zostały zainspirowane stosem Large Systems. Odporne na awarie serwery Tandem Computers również nosiły piętno tego arcydzieła inżynierii. Oprócz Forth, idee Burroughsa wywarły znaczący wpływ na Smalltalk, ojca wszystkich OOP, i oczywiście na architekturę maszyny wirtualnej JAVA.
Dlaczego tak wielkie maszyny wymarły?
Cóż, po pierwsze, nie wymarły natychmiast, klasyczna, prawdziwa architektura deskryptorów tagów Burroughsa była kontynuowana nieprzerwanie w linii mainframe UNISYS do 2010 roku, a dopiero potem straciła popularność na rzecz serwerów na banalnym Intel Xeon (z którym nawet IBM jest piekielnie trudno konkurować z). Przemieszczenie nastąpiło z jednego banalnego powodu, który zabił wszystkie inne egzotyczne samochody lat 1980.
W latach 1990. procesory ogólnego przeznaczenia, takie jak DEC Alpha i Intel Pentium Pro, osiągnęły tak niesamowitą wydajność, że wiele skomplikowanych sztuczek architektonicznych stało się zbędnych. SPARCserver-1000E na parze 90 MHz SuperSPARC-II pokonał Elbrusa we wszystkich opcjach jak boski żółw.
Drugim powodem upadku Burroughsa były te same problemy, które prawie zabiły Apple w latach 1980., zaostrzone przez skalę biznesu mainframe. Ich maszyny były tak złożone, że ich rozwój był niezwykle kosztowny i czasochłonny, więc w zasadzie tworzyli tylko nieznacznie ulepszone wersje tej samej architektury w latach 1970. Gdy tylko Burroughs próbował przenieść się gdzie indziej (jak w przypadku B6500 czy B8500), projekt zaczął się ślizgać, pochłaniać pieniądze z prędkością czarnej dziury i ostatecznie został anulowany (podobnie jak nieudane Apple III i Lisa) .
Skala komputerów mainframe oznaczała, że Burroughs sprzedawał komputery za miliony dolarów z niesamowicie kosztowną konserwacją. Np. B8500 miał mieć 16 procesorów, ale szacunkowy koszt konfiguracji nawet z trzema wyniósł ponad 14 mln dolarów, w związku z czym umowa na jego dostawę została rozwiązana.
Oprócz fenomenalnego kosztu samych maszyn, starsze komputery mainframe firmy wymagały ogromnych pieniędzy za wsparcie. Roczny pakiet utrzymania, serwisu i wszystkich licencji na całe oprogramowanie, w przypadku topowego modelu B7800, kosztował około 1 miliona dolarów rocznie, nie każdy mógł sobie pozwolić na taki luksus!
Zastanawiam się, czy sowieccy nafciarze kupili pełny serwis, czy sami naprawiali swoje Burroughsy, mocnym słowem i młotem?
Tak więc biznes Burroughsa zawsze utykał, brakowało mu skali i siły IBM. Nie mogli produkować tanich samochodów ze względu na złożoność rozwoju, a nabywcy drogich samochodów, biorąc pod uwagę aktywną walkę z konkurentami, nie wystarczyli, aby zwiększyć zyski i możliwość zainwestowania dodatkowych pieniędzy w rozwój i obniżenie cen, czyniąc samochody bardziej konkurencyjnymi.
Sperry UNIVAC miał te same problemy, ostatecznie w 1986 roku obie korporacje połączyły się, aby przetrwać, tworząc UNISYS, który od tamtej pory produkuje komputery typu mainframe.
Oprócz wspomnianych architektur Burtsev naprawdę wykorzystał doświadczenie 5E26 i 5E92b w zakresie sprzętowej kontroli błędów. Oba te komputery były zdolne do sprzętowego wykrywania i korygowania wszelkich jednobitowych błędów, aw projekcie Elbrus zasada ta została wzniesiona na nowy poziom.
Czekamy więc na odpowiedź na najbardziej fascynujące pytanie - czy Elbrus El Burrows?
Jak pamiętamy, Ailif porzucił klasyczny model von Neumanna, maszynę jako liniowy magazyn instrukcji i danych. Stos saguaro w Burroughs był strukturą drzewa odzwierciedlającą wykonywanie kodu równoległego i hierarchię procesów w wieloprogramowym środowisku wielu użytkowników. Nawiasem mówiąc, ALGOL ze swoją hierarchiczną strukturą bloków idealnie pasuje do stosu, dlatego jego implementacja w dużych systemach była tak udana.
Tę filozofię zintegrowanego projektowania w niebanalny sposób wypromowali architekci systemu Elbrus, którzy wynieśli ją na nowy poziom. W szczególności, zamiast kilku wyspecjalizowanych języków, grupa programistów z ITMiVT stworzyła jeden uniwersalny, podobny do Algola El-76.
Na tym architektoniczne nowości się nie skończyły.
Bezpośrednie porównanie maszyn przedstawia poniższa tabela, stary B6700 jako całość prezentuje się dobrze na tle komputera o 17 lat młodszego.
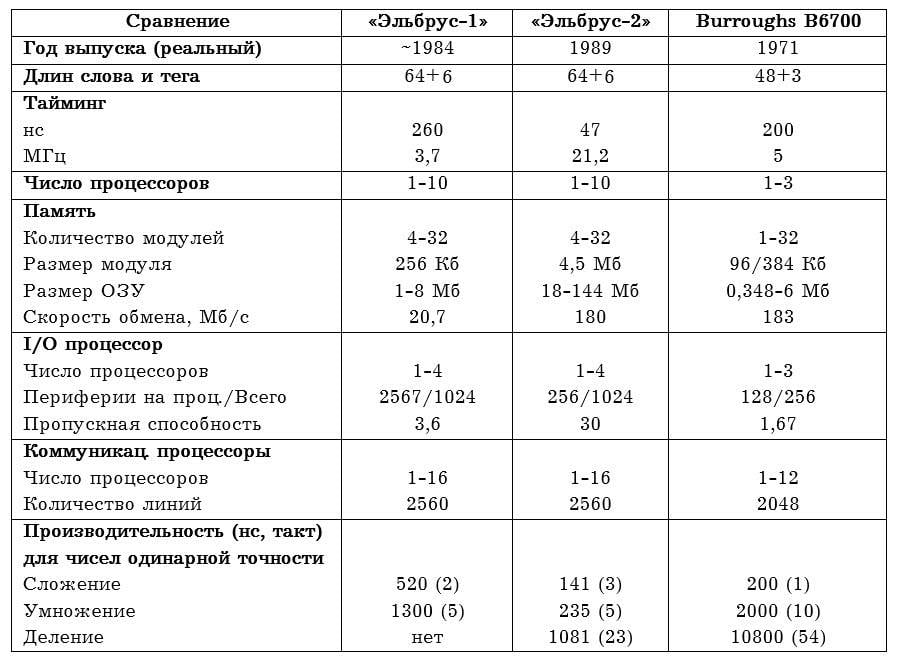
Z ciekawostek - w przeciwieństwie do B6700, Elbrus był potwornie ogromny.
Pierwsza wersja zajmowała 300 mkw. mw jednym procesorze i 1 mkw. mw konfiguracji 270-procesorowej, a drugi - odpowiednio 10 i niewiarygodne 420 mkw. m, odbierając tym samym laury największego komputera w historii od samego IBM AN/FSQ-2 Project SAGE, który jako lampowy zajmował 260 mkw. M.

Aby zrozumieć skalę. Stadion Wembley. Mniej więcej tyle zajmował kompleks wielomaszynowy Elbrus dla systemu obrony przeciwrakietowej A-135.
Procesor obu maszyn oparty jest na architekturze stosu CISC z odwróconą notacją polską. Kod skompilowanego programu składa się z zestawu segmentów. Segment zwykle odpowiada jednej procedurze lub blokowi w programie. Kiedy rozpoczyna się wykonywanie programu, przydzielane są dwie lokalizacje pamięci: jedna dla stosu i jedna dla słownika segmentów, który jest używany do odwoływania się do wielu segmentów programu w pamięci RAM. Obszary pamięci dla segmentów kodu i tablic są przydzielane przez system operacyjny na żądanie.
Deskryptory w obu maszynach są odpowiedzialne za ponowne wprowadzanie kodu poprzez organizowanie automatycznego współdzielenia pamięci między wykonującymi się wątkami. Kod i dane są ściśle oddzielone tagami, deskryptory pozwalają na uruchomienie identycznego kodu na różnych zestawach danych dla różnych użytkowników, z gwarancją ich ochrony.
Oba komputery używają nawet identycznych rejestrów specjalnego przeznaczenia (na przykład każda maszyna ma rejestry podstawy stosu, limitu stosu i rejestrów szczytu stosu) oraz instrukcje zarządzania stosem.
Burroughs i Elbrus mają bardzo podobną filozofię, ale znacznie różnią się konstrukcją samego procesora.
Procesor B6700 składa się z 48-bitowego sumatora, jednostki przetwarzania adresu, siedmiu kontrolerów funkcji (programu, arytmetyki, łańcuchów, dopasowania stosu, przerwania, przesyłania i pamięci) oraz zestawu rejestrów. Te ostatnie obejmują 4 51-bitowe rejestry danych (dwa górne elementy stosu, wartość bieżąca, wartość pośrednia) oraz 48 20-bitowych rejestrów instrukcji (32 rejestry wyświetlacza odpowiedzialne za przechowywanie punktów wejścia do aktualnie wykonywanych procedur i po 8 rejestrów bazowych adresów). i rejestry indeksowe).
Najciekawszą rzeczą w procesorze był niezwykle podstępny blok, tzw. kontrolery rodziny operacji (w ilości 10 sztuk), które z dostępnych bloków funkcjonalnych zbudowały potok obliczeniowy dla każdego polecenia. Pozwoliło to znacznie obniżyć koszt tranzystorów.
Kontroler przekazuje zdekodowaną instrukcję do rejestru Słowa Bieżącej Instrukcji Programowej i wybiera odpowiedni sterownik z rodziny operatorów. Kluczową cechą jest to, że instrukcje są wykonywane ściśle sekwencyjnie w kolejności narzuconej przez kompilator. Instrukcje arytmetyczne nie mogą się nakładać, ponieważ w CPU jest tylko jeden sumator.
To była główna różnica między procesorem Elbrus. Babayan z dumą bił się pięścią w pierś i ogłosił „pierwszy na świecie superskalar w Elbrusie” (który nie miał w ogóle nic wspólnego z rozwojem), ale w praktyce Burtsev dokładnie przestudiował architekturę wielkiego CDC 6600, aby nauczyć się tajemnice interakcji między grupami bloków funkcjonalnych w przenośnikach równoległych.
Z CDC 6600 Elbrus pożyczył architekturę wielu bloków funkcyjnych (w sumie 10): sumator, mnożnik, dzielnik, blok logiczny, blok konwersji kodowania BCD, blok wywołania operandu, blok zapisu operandu, blok przetwarzania łańcuchów, blok wykonania podprogramu i indeksowanie blok.
Istnieje pewne funkcjonalne nakładanie się tych bloków i kontrolerów B6700, ale są też istotne różnice, na przykład arytmetyka w Elbrusie ma 4 niezależne grupy zamiast jednej.
Wiele jednostek ALU było już używanych w innych maszynach, ale nigdy na świecie - na procesorze stosu. Oczywiście nie zrobiono tego z powodu wielkiej głupoty zachodnich programistów. Stos z definicji zakłada zerowe adresowanie - wszystkie niezbędne operandy muszą leżeć na wierzchu. Oczywiście przy braku tradycyjnych adresów tylko jedna operacja na cykl może poprawnie zaadresować górę - to w zasadzie wyklucza działanie bloków równoległych.
Grupa Burtseva musiała potwornie zboczyć, aby obejść to ograniczenie.
Tak naprawdę procesor stosu B6700 w wersji Elbrus w ogóle przestał być procesorem stosu! Cuda się nie zdarzają, a jeż nie krzyżuje się z wężem, więc wewnętrzna architektura, niewidoczna dla programisty, musiała być klasycznie rejestrowana. Kontroler odbiera i dekoduje polecenie w zwykły sposób, a następnie konwertuje je do formatu rejestru wewnętrznego. B6700 zinterpretował tylko 2 górne elementy stosu jako rejestry wewnętrzne, Elbrus - 32 elementy! W rzeczywistości ze stosu zostało tylko jedno nazwisko.
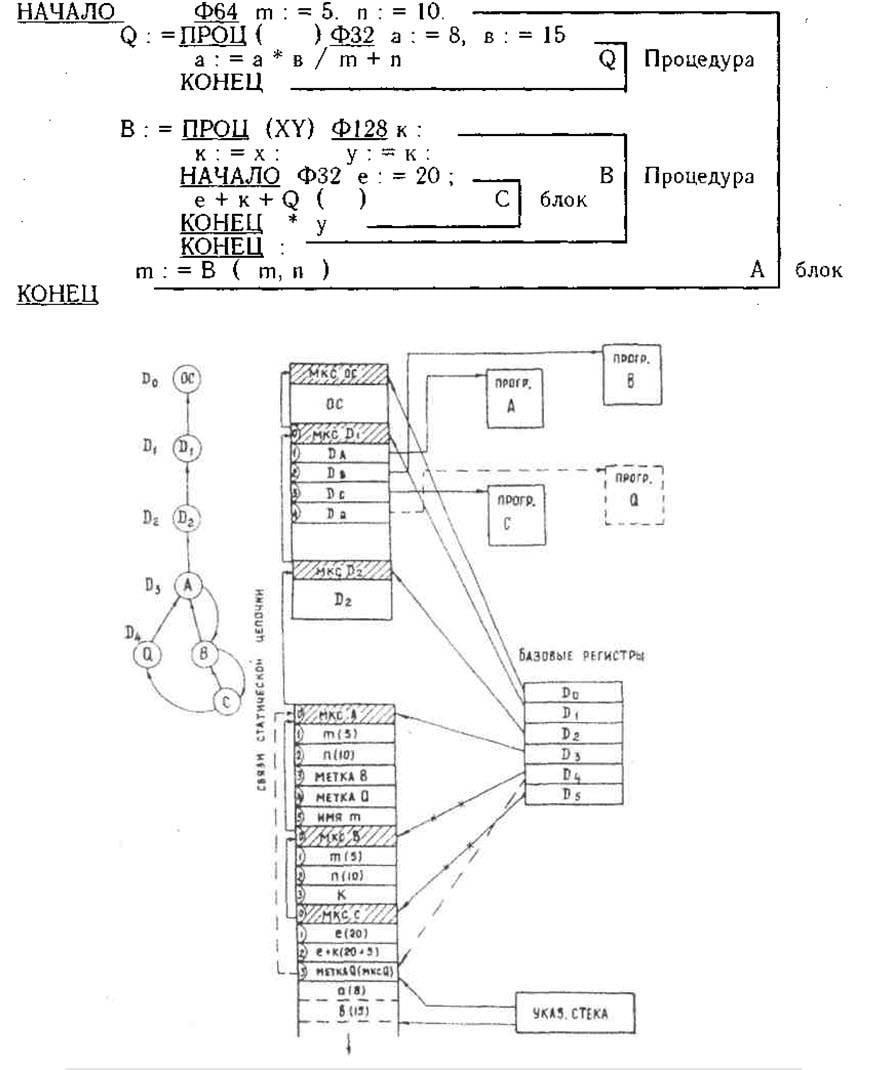
Stan pseudostosu Elbrusa w momencie przejścia do procedury Q. Z artykułu Burtseva „Zasady budowy wieloprocesorowych systemów obliczeniowych Elbrus”.
Oczywiście byłoby to całkowicie bezużyteczne, gdyby CU nie mogła ładować wszystkich funkcjonalnych urządzeń równolegle. Tak powstał mechanizm egzekucji spekulatywnej, który również jest absolutnie oryginalny.
Instrukcje Elbrus mogą być przekazywane do bloków funkcyjnych, zanim wszystkie wymagane operandy będą dostępne, po załadowaniu będą po prostu czekać na dane. W rzeczywistości wykonanie odbywa się zgodnie z zasadą architektury przepływu danych, dokładna kolejność wykonywania zależy od kolejności, w jakiej stają się dostępne operandy.
Co ostatecznie osiągnęli?
Cóż, reakcja współczesnego programisty na tak szalone decyzje jest oczywista:
Pamiętam, że praca z tablicami mnie zabiła. Przełączanie do trybu nadzorcy w celu przydzielenia tablicy — czy to normalne? Czy to normalne, że potok wykonania wie o tablicach? Praca z tablicami za pomocą deskryptora - czy to wydajne? Wpisanie poza zakresem jest szybsze do sprawdzenia, prawda? Aż strach pomyśleć, jak ten horror w ogóle spadnie na sprzęt. Jednak wtedy był inny układ z opóźnieniami i szybkością pamięci i innych komponentów, wcale nie taki sam jak teraz. Mogłaby usprawiedliwić tak śmiałe posunięcia, ale takie projekty w żaden sposób nie żyją. Właściwie nie przeżyły...
Teoretycznie twórcy czystych tag machine zaczęli od tego, że w połowie lat 1970. wciąż nie było architektur i kompilatorów zdolnych do przynajmniej częściowej automatycznej równoległości kodu, w wyniku czego większość systemów wieloprocesorowych nie dawała się efektywnie załadować całkowicie, a jednostki wykonawcze często były bezczynne. Wyjściem z tego impasu była architektura superskalarna lub osławione maszyny VLIW, ale do nich było jeszcze daleko (chociaż pierwszy superskalarny procesor wykorzystał ten sam Cray w CDC6600 jeszcze w 1965 roku, nie było tu jeszcze zapachu masowej produkcji ). I tak narodził się pomysł, aby ułatwić pracę programiście poprzez przeniesienie architektury do języka Java. Warto jednak zauważyć, że nie jest łatwo zrobić dobry superskalar na architekturze stosu - dużo łatwiej jest to zrobić dla systemów instrukcji RISC. Zobaczmy, jaki rodzaj superskalarny jest w Elbrusie-2: „Szybkość przetwarzania poleceń w urządzeniu sterującym może wahać się od dwóch poleceń na 1 cykl do jednego polecenia na 3 cykle. Najczęstsze kombinacje poleceń są przetwarzane z maksymalną szybkością: odczyt wartości i polecenie arytmetyczne; załaduj adres i pobierz element tablicy; pobierz adres i zapisz go."
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
Teoretycznie twórcy czystych tag machine zaczęli od tego, że w połowie lat 1970. wciąż nie było architektur i kompilatorów zdolnych do przynajmniej częściowej automatycznej równoległości kodu, w wyniku czego większość systemów wieloprocesorowych nie dawała się efektywnie załadować całkowicie, a jednostki wykonawcze często były bezczynne. Wyjściem z tego impasu była architektura superskalarna lub osławione maszyny VLIW, ale do nich było jeszcze daleko (chociaż pierwszy superskalarny procesor wykorzystał ten sam Cray w CDC6600 jeszcze w 1965 roku, nie było tu jeszcze zapachu masowej produkcji ). I tak narodził się pomysł, aby ułatwić pracę programiście poprzez przeniesienie architektury do języka Java. Warto jednak zauważyć, że nie jest łatwo zrobić dobry superskalar na architekturze stosu - dużo łatwiej jest to zrobić dla systemów instrukcji RISC. Zobaczmy, jaki rodzaj superskalarny jest w Elbrusie-2: „Szybkość przetwarzania poleceń w urządzeniu sterującym może wahać się od dwóch poleceń na 1 cykl do jednego polecenia na 3 cykle. Najczęstsze kombinacje poleceń są przetwarzane z maksymalną szybkością: odczyt wartości i polecenie arytmetyczne; załaduj adres i pobierz element tablicy; pobierz adres i zapisz go."
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
W zasadzie ZSRR w tym sensie pokonał samego siebie, maszyny Burroughsa, jak już wspomniano, nie obyły się bez takich bajerów nie z powodu głupoty ich architektów. Chcieli stworzyć czystą architekturę stosu i zrobili to dobrze.
W Elbrusie jedna nazwa pozostała z eleganckiej prostoty stosu, podczas gdy maszyna stała się o rząd wielkości droższa i bardziej skomplikowana (co to było do diabła z debugowaniem procesora Elbrusa, osoba, która to zrobiła, powie nam później), ale pod względem wydajności nadal tak naprawdę nie wygrał - otrzymał mieszankę wad obu klas maszyn.
Ogólnie rzecz biorąc, tak jest w przypadku, gdy lepiej byłoby ukraść ideę taką, jaka jest, bez prób jej sowietyzacji, czyli rozszerzenia i pogłębienia.
Co było tam o tablicach?
Burcew i tu wrzucił swoje 5 kopiejek.
W Burroughs B6700 dostęp do wszystkich elementów tablicy jest pośredni, poprzez indeksowanie za pomocą deskryptora tablicy. To wymaga dodatkowego cyklu. W Elbrusie postanowili usunąć ten cykl i dodali sprzętowy blok do wstępnego pobierania elementów tablicy do lokalnej pamięci podręcznej. Blok indeksu zawiera pamięć asocjacyjną, która przechowuje w pamięci adres bieżącego elementu wraz z krokiem.
W rezultacie uchwyt jest potrzebny tylko do wyciągnięcia pierwszego elementu tablicy; ze wszystkimi innymi można się skontaktować bezpośrednio. Pamięć asocjacyjna może pomieścić informacje o sześciu tablicach, a obliczenie adresu elementu w pętli zajmuje tylko jeden cykl, elementy tablicy dla nawet 5 iteracji pętli można z góry wyodrębnić.
Dzięki tej innowacji twórcy osiągnęli znaczne przyspieszenie operacji wektorowych na Elbrusie w porównaniu do B6700, który został zbudowany jako maszyna czysto skalarna.
Istotnym zmianom uległa również architektura pamięci.
B6700 nie miał pamięci podręcznej, tylko lokalny zestaw rejestrów specjalnego przeznaczenia. W Elbrusie pamięć podręczna składa się z czterech oddzielnych sekcji: bufora instrukcji (512 słów) do przechowywania instrukcji wykonywanych przez program, bufora stosu (256 słów) do przechowywania najbardziej aktywnej (najwyższej) części stosu, która w przeciwnym razie jest przechowywana w pamięci głównej; bufor tablicy (256 słów) do przechowywania elementów tablicy przetwarzanych cyklicznie; pamięć asocjacyjna dla danych globalnych (1 słów) dla danych innych niż te przechowywane w innych buforach. Obejmuje to zmienne globalne programu, uchwyty i lokalne dane procedur, które nie mieszczą się w buforze stosu.
Taka organizacja pamięci podręcznej umożliwiła efektywne włączenie stosunkowo dużej liczby procesorów do konfiguracji pamięci współdzielonej.
Jaki jest problem z przykręceniem pamięci podręcznej do systemu wieloprocesorowego?
Faktem jest, że każdy procesor może mieć swoją lokalną kopię danych, ale jeśli chcemy wymusić na procesorach przetwarzanie jednego zadania równolegle, to musimy zadbać o to, aby zawartość cache była identyczna.
Takie sprawdzenie nazywa się utrzymywaniem spójności pamięci podręcznej i wymaga wielu dostępów do pamięci RAM, co strasznie spowalnia system i zabija cały pomysł. Dlatego liczba procesorów w architekturze SMP - wieloprocesoryzmie symetrycznym rzadko przekracza 4 sztuki (nawet teraz 4 to klasyczna maksymalna liczba gniazd w serwerowej płycie głównej).
Dwuprocesorowy komputer mainframe IBM 3033 (1978) wykorzystywał prosty projekt z obsługą sklepu, w którym dane zmienione w pamięci podręcznej są natychmiast aktualizowane w pamięci RAM.
IBM 3084 (1982, 4 procesory) wykorzystywał bardziej zaawansowany schemat koherencji, w którym przesyłanie danych do pamięci RAM mogło być opóźniane do czasu nadpisania wpisów w pamięci podręcznej lub do uzyskania dostępu innego procesora do odpowiednich wpisów danych w pamięci głównej.
Dlatego 3-procesorowy B6700 obeszło się bez pamięci podręcznej - jego procesory były już zbyt fantazyjne.
Spójność pamięci podręcznej w Elbrusie została utrzymana dzięki wykorzystaniu koncepcji sekcji krytycznej w programie, dobrze znanej architektom systemów operacyjnych. Części programu, które uzyskują dostęp do zasobów (danych, plików, urządzeń peryferyjnych) współdzielonych przez kilka procesorów, w momencie dostępu ustawiają specjalny semafor, co oznacza wejście do sekcji krytycznej, po czym zasób zostaje zablokowany dla wszystkich pozostałych procesorów. Po wyjściu z niego zasób został ponownie odblokowany.
Biorąc pod uwagę, że sekcje krytyczne stanowiły (przynajmniej według dewelopera) około 1% przeciętnego programu, 99% współdzielenia pamięci podręcznej nie wiązało się z kosztami utrzymania spójności. Instrukcje w buforze instrukcji są z definicji statyczne, więc ich kopie w wielu pamięciach podręcznych pozostają identyczne. To jeden z powodów, dla których Elbrus obsługiwał aż 10 procesorów.
Ogólnie jego architektura jest przykładem bardzo wczesnego wykorzystania segmentowanej pamięci podręcznej, podobna zasada (bufor stosu, bufor instrukcji i bufor pamięci asocjacyjnej) była już zaimplementowana w B7700, ale wyszła w 1976 roku, kiedy większość zakończono prace nad stworzeniem architektury Elbrusa.
Tym samym Elbrus zasłużenie otrzymuje miano jednego z pierwszych na świecie systemów ogólnego przeznaczenia z pamięcią współdzieloną przez 10 procesorów.
Technicznie (biorąc pod uwagę fakt, że Elbrus-2 działał normalnie dopiero w 1989 roku), pierwszym wydanym superkomputerem tego typu był Sequent Balance 8000 z 12 procesorami National Semiconductor NS32032 (1984; wersja Balance 1986 z 21000 procesorami została wydana w 30 roku ), ale sam pomysł wpadł grupie Burcewa zdecydowanie dziesięć lat wcześniej.
Model pamięci Elbrusa okazał się niezwykle skuteczny.
Np. wykonanie prostego programu w stylu dodawania kilku numerów z wymaganym przepisaniem w przypadku S/360 z 620 dostępów do pamięci (jeśli napisano w ALGOL) do 46 (jeśli w asemblerze), 396 i 54 w przypadku BESM-6 i tylko 23 w "Elbrusie".
Podobnie jak maszyny Burroughsa, Elbrus używa tagów, ale ich użycie było wielokrotnie rozszerzane.
W swoim dążeniu do przeniesienia jak największej kontroli na sprzęt, grupa Burtseva podwoiła długość znacznika do 6 bitów. W rezultacie maszyna była w stanie rozróżnić operandy o połowicznej/pojedynczej/podwójnej precyzji, liczby całkowite/rzeczywiste, puste/pełne słowa, etykiety (w tym takie specjalistyczne rzeczy, jak „uprzywilejowana etykieta bez zewnętrznego bloku przerwań” i „etykieta bez informacji o adresie rejestrator"), semafory, słowa kontrolne i inne.
Jednym z głównych celów tworzenia etykiet było uproszczenie programowania. Gdyby bloki funkcyjne mogły rozróżniać operandy rzeczywiste i całkowite, można by je zaprojektować tak, aby dostosowywały się do obliczeń na obu i nie byłoby potrzeby stosowania oddzielnych bloków skalarnych i rzeczywistych.
W rzeczywistości Elbrus zaimplementował dynamiczne pisanie na poziomie porównywalnym do współczesnego OOP i sprzętowo.
Innym celem tagów było wykrywanie błędów, takich jak próba wykonania operacji arytmetycznej na instrukcji, tagi mogły również służyć do ochrony pamięci, ograniczenia zapisu niektórych danych itp.
W dziedzinie tagów Elbrus przeniósł idee maszyny podstawowej i B6700 na nowy poziom wyrafinowania.
Wszystko to pozwoliło osiągnąć to, czego nie osiągnęli architekci z Burroughs. Jak pamiętamy, potrzebowali osobnych rozszerzeń ALGOL do pisania kodu systemu operacyjnego i późniejszego zarządzania systemem. Twórcy „Elbrusa” porzucili ten pomysł i stworzyli jeden kompletny uniwersalny język „El-76”, w którym wszystko można było napisać.
Napisanie całego systemu operacyjnego w języku wysokiego poziomu (w tym kodu odpowiedzialnego za wewnętrzne elementy najniższego poziomu, takie jak alokacja pamięci i przełączanie procesów) wymaga specjalnego sprzętu bardzo wysokiego poziomu. Na przykład przełączanie procesów w Elbrus OS zostało zaimplementowane jako sekwencja operatorów przypisania, które wykonują dobrze zdefiniowane akcje na specjalnych rejestrach sprzętowych.
Konstrukcja pamięci RAM w obu maszynach jest niezwykle podobna, choć Elbrus (zwłaszcza w drugiej wersji) zawiera znacznie więcej pamięci.
Pamięć RAM „Elbrus” jest zorganizowana hierarchicznie, sekcja pamięci (1 szafka) składa się z 4 modułów, każdy moduł zawiera 32 bloki po 16 słów. Naprzemienność jest możliwa na kilku poziomach: między sekcjami, między modułami w ramach sekcji oraz w ramach poszczególnych modułów. Z każdego modułu pamięci można odczytać do czterech słów w jednym cyklu. Maksymalna przepustowość pamięci wynosi 450 MB/s, chociaż maksymalna szybkość przesyłania danych z każdym procesorem wynosi 180 MB/s.
Schematy zarządzania pamięcią w B6700 i Elbrusie są generalnie bardzo podobne. Pamięć jest zorganizowana w segmenty o zmiennej długości, które reprezentują logiczne sekcje programu zdefiniowane przez kompilator. Zgodnie z logicznym podziałem programu, segmenty mogą mieć różne poziomy ochrony i być współdzielone między procesami.
W modelu B6700 segmenty przemieszczały się między pamięcią główną a pamięcią wirtualną jako całością. Wyjątkiem były tablice. Mogły być przechowywane w pamięci głównej w grupach po 256 słów każda, ograniczonych z obu stron słowami łączącymi.
W Elbrusie segmenty kodu są traktowane inaczej niż segmenty danych i tablice. Kod jest przetwarzany w taki sam sposób jak w B6700, a dane i tablice są zorganizowane w strony po 512 słów każda.
Podejście Elbrusa jest tutaj bardziej wydajne i umożliwia szybszą wymianę.
Ponadto Elbrus wykorzystuje bardziej nowoczesny typ pamięci wirtualnej.
W komputerach Burroughs adresowanie było ograniczone do 20 bitów lub 220 słów, maksymalnej pamięci fizycznej w B6700/7700. O obecności segmentów w pamięci głównej informował specjalny bit w ich deskryptorze, który pozostawał w pamięci RAM podczas wykonywania procesu. Nie istniała koncepcja rzeczywistej przestrzeni pamięci wirtualnej, która byłaby większa niż całkowita ilość pamięci fizycznej; deskryptory zawierały tylko adresy fizyczne.
Maszyny Elbrus wykorzystywały podobny 20-bitowy schemat adresowania dla segmentów programu, ale adresowanie 32-bitowe było używane dla segmentów danych i tablic stałych. Dało to przestrzeń pamięci wirtualnej o wielkości 232 bajtów (4 gigabajty). Segmenty te zostały przeniesione między pamięcią wirtualną i fizyczną przy użyciu mechanizmu stronicowania, który wykorzystywał tablice stronicowania przechowywane w bloku asocjacyjnym pamięci stronicowania do konwersji między adresami wirtualnymi i fizycznymi. Adresy wirtualne składają się z numeru strony i przesunięcia w obrębie strony. Jest to właściwie pełnoprawna nowoczesna implementacja pamięci wirtualnej, taka sama jak w maszynach IBM.
Więc jaki jest nasz werdykt?
Elbrus zdecydowanie nie był kompletnym klonem Burroughsa B6700 (a nawet B7700).
Co więcej, nie był nawet jego ideowym klonem, a raczej jego bratem, ponieważ zarówno B6700, jak i Elbrus czerpały inspirację z tego samego źródła – prac Ailifa nad maszyną bazową i prac Uniwersytetu w Manchesterze oraz wspólnego przodka B -seria, słynny B5000, była rozwinięciem idei zawartych w samochodzie Rice'a R1. Ponadto Elbrus jako inspirację wykorzystał CDC 6600 (gdzie bez niego), aw zakresie pracy z pamięcią wirtualną - IBM S/360 model 81.
W związku z tym bez wątpienia przyznajemy, że sama architektura Elbrusa była absolutnie w nurcie światowego rozwoju lat 1970. i była ich godnym przedstawicielem.
Co więcej, pod wieloma względami był znacznie bardziej zaawansowany niż B6700/7700.
Być może dopiero próby osiągnięcia superskalaryzmu można uznać za naprawdę nieudaną decyzję, która zakończyła się fiaskiem zarówno architektonicznym (superskalar na 2–3 operacje, jak już wspomniano, nie jest wart świeczki), jak i praktycznym (w efekcie już potwornie złożony procesor stał się jeszcze bardziej złożony, zajmując ogromną szafkę w kształcie litery T i prawie niemożliwy do debugowania, dlatego przez tyle lat był zamieszany z punktami widzenia.
Niestety, żeby ominąć takie momenty, trzeba mieć kolosalne doświadczenie i intuicję, wypracowaną przez lata pracy z najlepszymi przykładami światowej architektury, której w Unii oczywiście nie było.
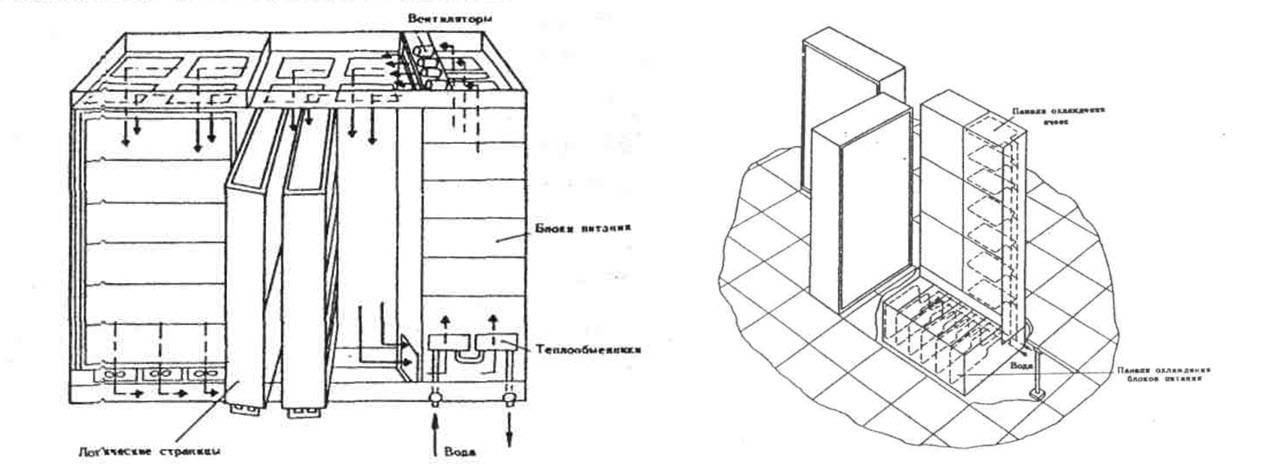
Typowa szafa „Elbrus-1” i procesor „Elbrus-2” z artykułu Burtseva „Równoległość procesów obliczeniowych a rozwój architektury superkomputera. MVC „Elbrus”.
Oczywiście nie należy mówić o żadnej oryginalności Elbrusa - w rzeczywistości była to tylko kompilacja różnych rozwiązań technicznych, znacznie ulepszonych w niektórych aspektach.
Ale z tego punktu widzenia B5000 był również bardzo zaawansowaną wersją R1, jak już powiedzieliśmy.
Nie ma też wątpliwości co do aktualności takiej architektury teraz – lata 1970. już dawno minęły, historia IT obróciła się w zupełnie innym kierunku i zmierza tam od 40 lat.
Tak więc na papierze „Elbrus” według standardów z 1970 roku był bez wątpienia arcydziełem, porównywalnym z najlepszymi zachodnimi samochodami. A oto jego realizacja...
Jest to jednak temat na kolejny artykuł.
To be continued ...
informacja